介绍
Spring自带了一组数据访问框架,集成了多种数据访问技术。不管是直接通过JDBC还是像Hibernate这样的对象关系映射(object-relational mapping,ORM)框架实现数据持久化,或是java持久化API(Java Persistence API,JPA),或是NoSQL数据库等。Spring都能够消除持久化代码中那些单调枯燥的数据访问逻辑。
Spring访问数据的原理
Spring对数据库访问的支持也是遵循面向对象原则中的针对接口编程。为了避免持久化的逻辑分散到应用的各个组件中,Spring将数据访问的功能放到一个或多个专注于此项任务的组件中,这样的组件通常称为数据访问对象(data access object,DAO)或Repository。为了避免应用于特定的数据访问策略耦合在一起,编写良好的Repository应该以接口的方式暴露功能。如下图:
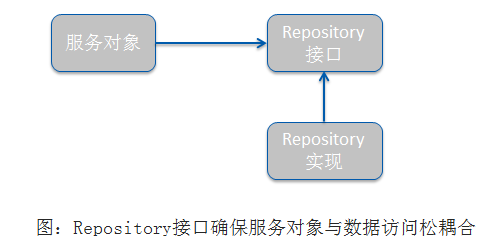
这里说明一点,尽管Spring鼓励使用接口,但并不是强制的,你也可以使用Spring将bean(DAO或其他类型)直接装配到另一个bean的某个属性中,而不需要一定通过接口注入。
Spring数据访问异常体系
Spring提供多个数据访问异常,分别描述了它们抛出时所对应的问题。Spring所提供的持久化异常是与平台无关的,这意味着我们可以使用Spring抛出一致的异常,而不用关心所选择的持久化方案。Spring所提供的异常都继承自DataAccessException,这是一个非检查型异常。换句话说,没必要捕获Spring所抛出的数据访问异常。因为Spring认为触发异常的很多问题是不能再catch块中修复的,所以使用了非检查型异常,而不是强制开发人员编写catch块代码(里面经常是空的)。
数据访问模板
为了利用Spring的数据访问异常,我们必须使用Spring所支持的数据访问模板。Spring将数据访问过程中固定的和可变的部分明确划分为两个不同的类:模板(template)和回调(callback)。模板管理过程中固定的部分,而回调处理自定义的数据访问代码。如下图:
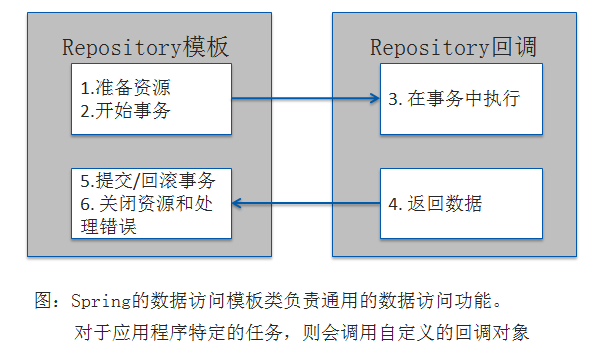
如图所示,Spring的模板类处理数据访问的固定部分——事务控制、管理资源以及处理异常。 同时, 应用程序相关的数据访问——语句、绑定参数以及整理结果集——在回调的实现中处理。 针对不同的持久化平台, Spring提供了多个可选的模板 。
| 模板类(org.springframework.*) | 用途 |
|---|---|
| jca.cci.core.CciTemplate | JCA CCI连接 |
| jdbc.core.JdbcTemplate | JDBC连接 |
| jdbc.core.namedparam.NamedParameterJdbcTemplate | 支持命名参数的JDBC连接 |
| jdbc.core.simple.SimpleJdbcTemplate | 通过java5简化的jdbc连接 |
| orm.hibernate3.HibernateTemplate | Hibernate 3.x以上的Session |
| orm.ibatis.SqlMapClientTemplate | IBATIS SqlMap客户端 |
| orm.jdo.JdoTemplate | java数据对象(Java Data Object)实现 |
| orm.jpa.JpaTemplate | java持久化API的实体管理器 |
配置数据源
无论选择哪种数据访问方式, 都需要配置一个数据源的引用。 Spring提供了在Spring上下文中配置数据源bean的多种方式, 包括:
- 通过JDBC驱动程序定义的数据源;
- 通过JNDI查找的数据源;
- 连接池的数据源。
使用JNDI数据源
Spring应用程序经常部署在Java EE应用服务器中, 如WebSphere、JBoss或甚至像Tomcat这样的Web容器中。 这些服务器允许你配置通过JNDI获取数据源。 这种配置的好处在于数据源完全可以在应用程序之外进行管理, 这样应用程序只需在访问数据库的时候查找数据源就可以了。 另外, 在应用服务器中管理的数据源通常以池的方式组织, 从而具备更好的性能, 并且还支持系统管理员对其进行热切换。
使用Spring bean将JNDI中数据源的引用装配到需要的类中:
1 | <jee:jndi-lookup id="dataSource" jndi-name="/jdbc/SpitterDS" resource-ref="true" /> |
其中jndi-name属性用于指定JNDI中资源的名称。 如果只设置了jndi-name属性, 那么就会根据指定的名称查找数据源。 但是, 如果应用程序运行在Java应用服务器中, 你需要将resource-ref属性设置为true, 这样给定的jndi-name将会自动添加“java:comp/env/”前缀。
使用java配置:
1 |
|
使用数据源连接池
Spring没有提供数据源连接池实现,我们可以使用如下的开源实现:
例:配置DBCP BasicDataSource:
1 | //xml配置 |
DBCP BasicDataSource的池配置属性:
| 池配置属性 | 所指定的内容 |
|---|---|
| initialSize | 池启动时创建的连接数量 |
| maxActive | 同一时间可从池中分配的最多的连接数。设置0表示无限制 |
| maxIdle | 池里被释放的最多空闲连接数。设置0表示无限制 |
| maxOpenPreparedStatements | 在同一时间能够从语句池中分配的预处理语句(prepared statement)的最大数量。设置0表示无限制 |
| maxWait | 在抛出异常前,池等待连接回收的最大时间。设置-1表示无限等待 |
| minEvictableIdleTimeMillis | 连接在池中保持空闲而不被回收的最大时间 |
| minIdle | 在不创建新连接的情况下,池中保持空闲的最小连接数 |
| poolPreparedStatements | 是否对预处理语句进行池管理 |
基于JDBC驱动的数据源
Spring提供了三个这样的数据源类( 均位于org.springframework.jdbc.datasource包中) 供选择:
- DriverManagerDataSource: 在每个连接请求时都会返回一个新建的连接。 与DBCP的BasicDataSource不同,由DriverManagerDataSource提供的连接并没有进行池化管理;
- SimpleDriverDataSource:与DriverManagerDataSource的工作方式类似, 但是它直接使用JDBC驱动, 来解决在特定环境下的类加载问题, 这样的环境包括OSGi容器;
- SingleConnectionDataSource: 在每个连接请求时都会返回同一个的连接。 尽管SingleConnectionDataSource不是
严格意义上的连接池数据源, 但是你可以将其视为只有一个连接的池。
例:DriverManagerDataSource配置:
1 | //xml配置 |
局限性:
尽管这些数据源对于小应用或开发环境来说是不错的, 但是要将其用于生产环境, 你还是需要慎重考虑。 因为SingleConnectionDataSource有且只有一个数据库连接, 所以不适合用于多线程的应用程序, 最好只在测试的时候使用。
而DriverManagerDataSource和SimpleDriverDataSource尽管支持多线程, 但是在每次请求连接的时候都会创建新连接, 这是以性能为代价的。 鉴于以上的这些限制,所以建议应该使用数据源连接池。
使用嵌入式的数据源
嵌入式数据库( embedded database)作为应用的一部分运行, 而不是应用连接的独立数据库服务器。 尽管在生产环境的设置中, 它并没有太大的用处, 但是对于开发和测试来讲, 嵌入式数据库都是很好的可选方案。 这是因为每次重启应用或运行测试的时候, 都能够重新填充测试数据。
使用jdbc命名空间配置嵌入式数据库:
1 | //xml配置 |
使用profile选择数据源
对于开发期来说, jdbc:embedded-database元素是很合适的, 而在QA环境中, 你可能希望使用DBCP的BasicDataSource, 在生产部署环境下, 可能需要使用jee:jndi-lookup。借助Spring的profile特性能够在运行时选择数据源:取决于profile的激活状态
1 | //java配置 |
Spring中使用JDBC
Spring为JDBC提供了三个模板类供选择:
- JdbcTemplate: 最基本的Spring JDBC模板, 这个模板支持简单的JDBC数据库访问功能以及基于索引参数的查询;
- NamedParameterJdbcTemplate: 使用该模板类执行查询时可以将值以命名参数的形式绑定到SQL中, 而不是使用简单的索引参数;
- SimpleJdbcTemplate: 该模板类利用Java 5的一些特性如自动装箱、 泛型以及可变参数列表来简化JDBC模板的使用。(spring3.1废弃,java 5特性转移到JdbcTemplate)
使用JdbcTemplate来操作数据
在spring中配置JdbcTemplate:
1 |
|
将jdbcTemplate装配到Repository中并使用它来访问数据库:例如, SpitterRepository使用了JdbcTemplate
1 | /* |
在Repository中具备可用的JdbcTemplate后, 我们可以极大地简化JDBC操作数据库的代码。
例1:基于JdbcTemplate的addSpitter()方法
1 | //样板代码被隐藏到JDBC模板类中了,Spring的数据访问异常都是运行时异常, 所以不必在addSpring ()方法中进行捕获 |
例2:使用JdbcTemplate查询Spitter
1 | //findOne()方法, 使用了JdbcTemplate的回调, 实现根据ID查询Spitter, 并将结果集映射为Spitter对象 |
在JdbcTemplate中使用Java 8的Lambda表达式
因为RowMapper接口只声明了addRow()这一个方法, 因此它完全符合函数式接口( functional interface) 的标准。如果使用Java 8来开发应用的话, 我们可以使用Lambda来表达RowMapper的实现, 而不必再使用具体的实现类了。如改写findOne()方法:
1 | //使用Java 8的Lambda表达式 |
另外, 还可以使用Java 8的方法引用, 在单独的方法中定义映射逻辑:
1 | public Spitter findOne(long id){ |
不管采用哪种方式, 我们都不必显式实现RowMapper接口, 但是与实现RowMapper类似, 我们所提供的Lambda表达式和方法必须要接受相同的参数, 并返回相同的类型。
使用命名参数
命名参数可以赋予SQL中的每个参数一个明确的名字, 在绑定值到查询语句的时候就通过该名字来引用参数。声明NamedParameterJdbcTemplate:
1 |
|
将NamedParameterJdbcOperations( NamedParameterJdbcTemplate所实现的接口) 注入到Repository中, 用它来替代JdbcOperations。 现在的addSpitter()方法如下所示:
1 | private static final String INSERT_SPITTER = |