介绍
在一颗含有N个结点的树中,我们希望树高为~lgN,这样就能保证所有查找都能在~lgN次比较内结束,就和二分查找一样。但是在动态插入中保持树的完美平衡的代价太高了。
定义:一颗二叉查找树(BST)是一颗二叉树,其中每个结点都含有一个Comparable的键(以及相关联的值)且每个结点的键都大于其左子树中的任意结点的键而小于右子树的任意结点的键。二叉查找树如下图:
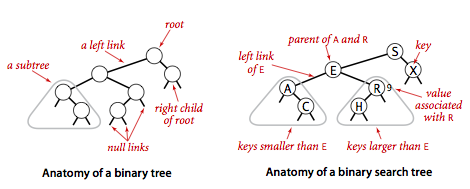
在二叉树中,每个结点只能有一个父结点(根结点没有父结点),每个结点包含的链接可以为空或者只有左右两个链接,分别指向自己的左子结点和右子结点。因此可以将二叉查找树定义为一个空链接,或者是一个有左右两个链接的结点,每个链接都指向一颗独立的子二叉树。二叉查找树是一种能够将链表插入的灵活性和有序数组查找的高效性结合起来的符号表实现。具体来说,就是使用每个结点含有两个链接 (链表中每个结点只含有一个链接)的二叉查找树来高效的实现符号表。
定义:符号表是一种存储键值对的数据结构,支持两种操作:插入(put),即将一组新的键值对存入表中;查找(get),即根据给定的键得到相应的值。
一种简单得泛型符号表API:
| public class ST<Key, Value> | 描述 | 默认实现 |
|---|---|---|
| ST() | 创建一张符号表 | |
| void put(Key key, Value val) | 将键值对存入表中(若值为空则将键key从表中删除) | |
| Value get(Key key) | 获取键key对应的值(若键key不存在则返回null) | |
| void delete(Key key) | 从表中删除键key(及其对应的值) | put(key, null) |
| boolean contains(key key) | 键key在表中是否有对应的值 | return get(key) != null |
| boolean isEmpty() | 表是否为空 | return size() == 0 |
| int size() | 表中键值对数量 | |
| Iterable |
表中所有键的集合 |
说明:
MySQL 客户端连接成功后,通过show [session|global] status 命令可以提供服务器状态信息,也可以在操作系统上使用 mysqladmin extended-status 命令获得这些消息。show [session|global] status 可以根据需要加上参数session或者global来显示 session 级(当前连接)的统计结果和 global 级(自数据库上次启动至今)的统计结果。如果不写默认使用参数是session。
Com_xxx 表示每个 xxx 语句执行的次数,我们通常比较关心的是以下几个统计参数:
上面这些参数对于所有存储引擎的表操作都会进行累计。
本节针对sql优化的常见优化点做一总结:
对查询进行优化,应尽量避免全表扫描,首先应考虑在where及order by 涉及的列上建立索引。
避免在where子句中使用is null 或 is not null对字段进行判断。
1 | select id from table where name is null |
在这个查询中,就算我们为 name 字段设置了索引,查询分析器也不会使用,因此查询效率底下。为了避免这样的查询,在数据库设计的时候,尽量将可能会出现 null 值的字段设置默认值,这里如果我们将 name 字段的默认值设置为0,那么我们就可以这样查询:
1 | select id from table where name = 0 |
数据库索引是数据库管理系统中一个排序的数据结构,以协助快速查询、更新数据库表中数据。索引的实现通常使用B树及其变种B+树。
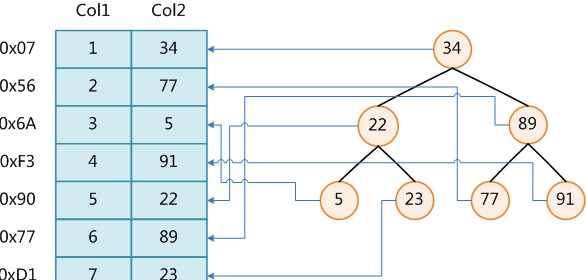
下图展示了一种可能的索引方式。左边是数据表,一共有两列七条记录,最左边的是数据记录的物理地址(注意逻辑上相邻的记录在磁盘上也并不是一定物理相邻的)。为了加快Col2的查找,可以维护一个右边所示的二叉查找树,每个节点分别包含索引键值和一个指向对应数据记录物理地址的指针,这样就可以运用二叉查找在O(log2n)的复杂度内获取到相应数据。
Redis的字符串就是一个由字节组成的序列,在Redis里面,字符串可以存储以下3中类型的值:
Redis对字符串执行自增和自减的命令:
| 命令 | 用例和描述 |
|---|---|
| INCR | INCR key-name ———将键存储的值加1 |
| DECR | DECR key-name ———将键存储的值减去1 |
| INCRBY | INCRBY key-name amount ——-将键存储的值加上整数amount |
| DECRBY | DECRBY key-name amount ——-将键存储的值减去整数amount |
| INCRBYFLOAT | INCRBYFLOAT key-name amount ——-将键存储的值加上浮点数amount,redis2.6及以上可用 |
Redis是一个速度非常快的非关系数据库(non-relational database),它能够自动以两种不同的方式将数据写入硬盘,可以存储键与5种不同类型的值之间的映射,可以将存储在内存的键值对数据持久化到硬盘,可以使用复制特性来扩展读性能,还可以使用客户端分片来扩展写性能。Redis不使用表,它的数据库也不会预定义或者强制去要求用户对Redis存储的不同数据进行关联。
分片是一种将数据划分为多个部分的方法,对数据的划分可以基于键包含的ID、基于键的散列值,或者基于以上两者的某种组合。通过对数据进行分片,用户可以将数据存储到多台机器里面,也可以从多台机器里面获取数据,这种方法在解决某些问题时可以获得线性级别的性能提升。
在数据持久化的世界中, JDBC能很好地完成份内的事并且在一些特定的场景下表现出色。 但此外,我们还需要一些更复杂的特性:
一些可用的框架提供了这样的服务, 这些服务的通用名称是对象/关系映射(object-relational mapping, ORM)。