介绍
快速排序是一种分治的排序算法。它将一个数组分成两个子数组,将两部分独立地排序,当两个子数组都有序时整个数组也就有序了。快速排序和归并排序是互补的:归并排序将数组分成两个子数组分别排序,并将有序的子数组归并以将整个数组排序。归并排序将一个数组等分成两半,递归调用发生在处理整个数组之前;快速排序切分(partition)的位置取决于数组的内容,递归调用发生在处理整个数组之后。快速排序示意图:
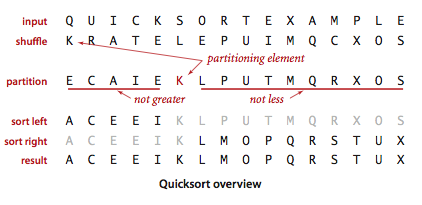
排序就是将一组对象按照某种逻辑顺序重新排列的过程。排序算法的目标是将所有元素的主键按照某种方式排列。在java中,元素通常都是对象,对主键的描述则是通过一种内置的机制—Comparable接口。
排序算法类的模板:
1 | /** |
输入一系列整数对,其中每个整数都表示一个某种类型的对象,一对整数p和q可以理解成“p和q是相连的”。我们假设“相连”是一种等价关系,这意味着它具有:
当程序从输入中读取了整数对p,q时,如果已知的所有整数对都不能说明p和q是相连的,则将这对整数写到输出,如果已知的数据可以说明p和q是相连的,则忽略这对整数对继续处理下一对整数对。要求程序能够判断给定的整数对是否相连。
我们程序限定为网络问题,所以使用网络方面的术语:将对象称为触点,将整数对称为连接,将等价类称为连通分量。
union-find算法的API:
| public class UF | |
|---|---|
| UF(int N) | 以整数标识(0到N-1初始化N个触点) |
| void union(int p, int q) | 在p和q之间建立连接,合并分量 |
| int find(int p) | p所在的分量的标识符 |
| boolean connected(int p, int q) | 如果p和q存在于同一个分量中则返回true |
| int count() | 连通分量的数量 |
栈是一种基于后进先出(LIFO)策略的集合类型。在应用程序中使用栈迭代器的一个典型原因是在用集合保存元素的同时颠倒它们的顺序。栈的一个典型用例:把标准输入的所有整数逆序排列。
1 | public class StackOfType { |
